Results on emg2qwerty
Comparison between our method and emg2qwerty baselines (average over 8 subjects). Lower CER is better; improvement is statistically significant (p < 0.015). LM: language model.
| Model | No LM (Val) | No LM (Test) | 6-gram LM (Val) | 6-gram LM (Test) |
|---|---|---|---|---|
| Baseline (spectrogram) — emg2qwerty | 15.65 ± 5.95 | 15.38 ± 5.88 | 11.03 ± 4.45 | 9.55 ± 5.16 |
| Matrices σ(τ) (ours) | 14.33 ± 5.27 | 14.03 ± 5.27 | 9.61 ± 3.84 | 7.95 ± 4.54 |
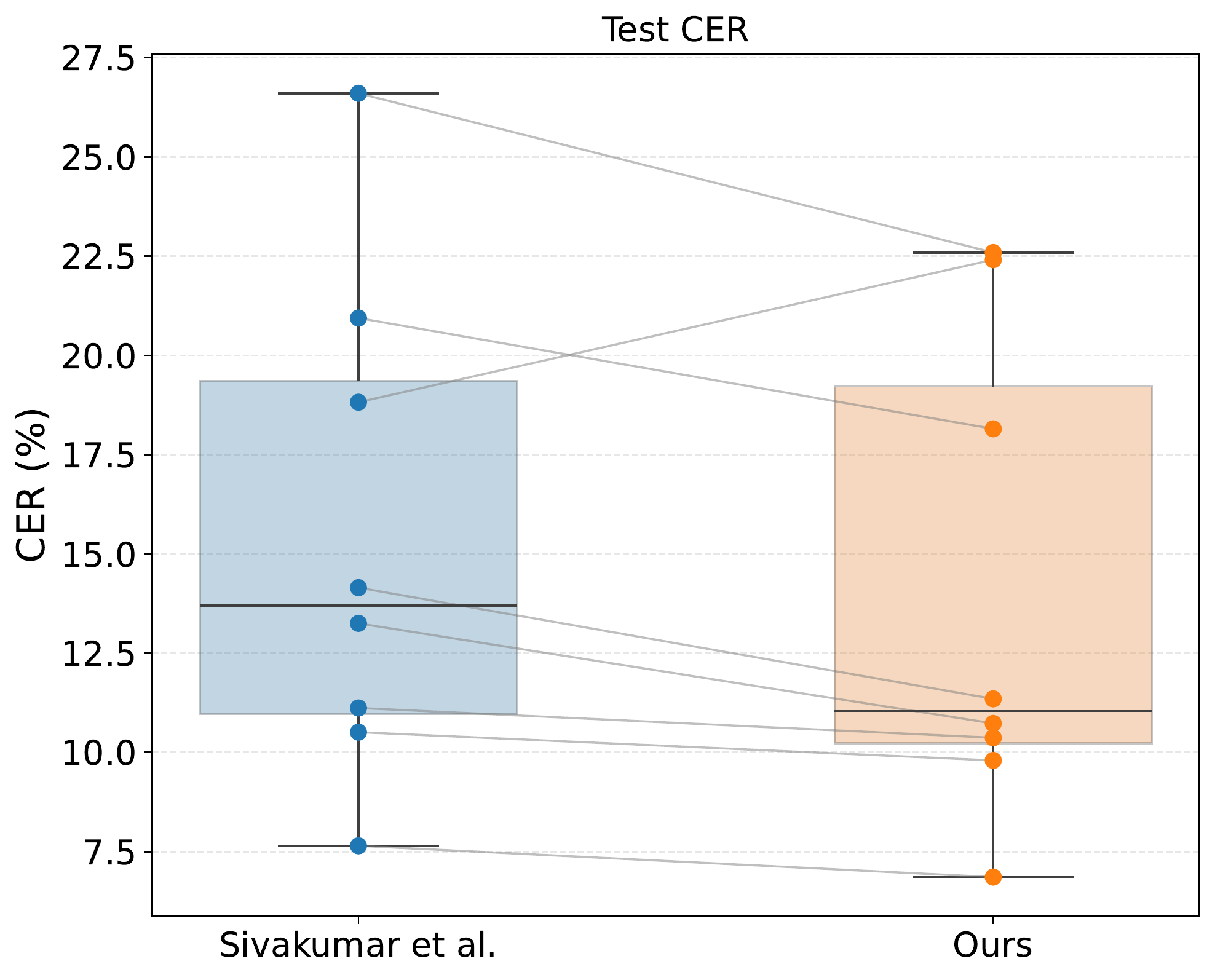
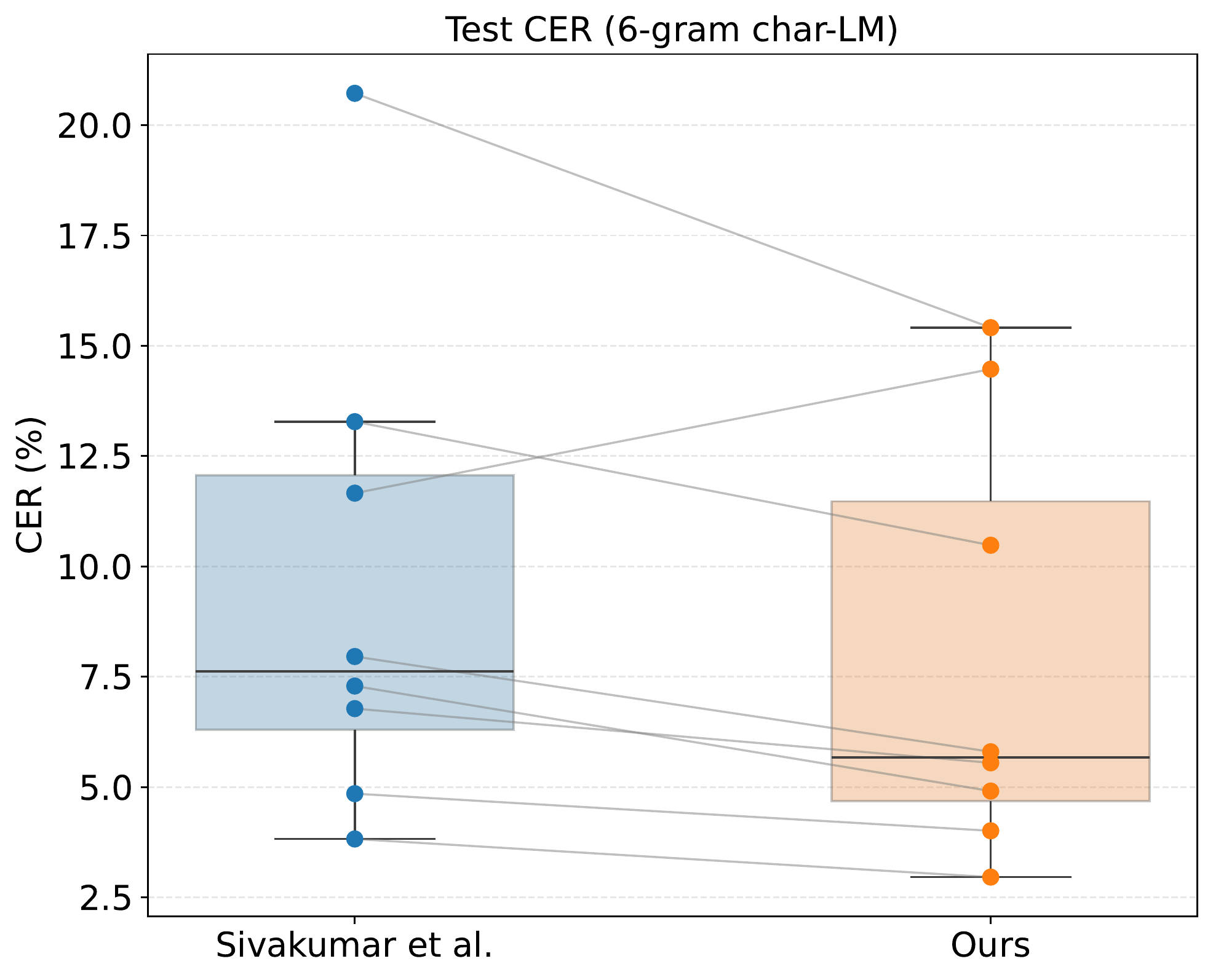
Each dot represents an individual test subject; lines connect within-subject results across models. Our method improves performance for all subjects except user6.